Extract Tabular Data from PDF with Python and Transpose Multiple Columns using Python

Data collection or data collection is the process of collecting and ascertaining information on the variable of interest (subject to be tested), in a systematic way that allows one to answer questions from the trials conducted, test hypotheses, and evaluate the results. There are many types of documents that we can extract in python, on this opportunity I will explain how to extract a pdf document type easily in python.
Extract Tabular Data from PDF with Python
PDF is one of the most vital and extensively used digital media. used to current and trade documents. PDFs include useful information, hyperlinks and buttons, structure fields, audio, video, and enterprise logic. PDF processing comes below textual content analytics. Most of the text analytics library or frameworks are designed in Python only. This offers leverage on textual content analytics. Once you extract the beneficial facts from PDF you can without problems use that facts into any Machine Learning or Natural Language Processing Model.
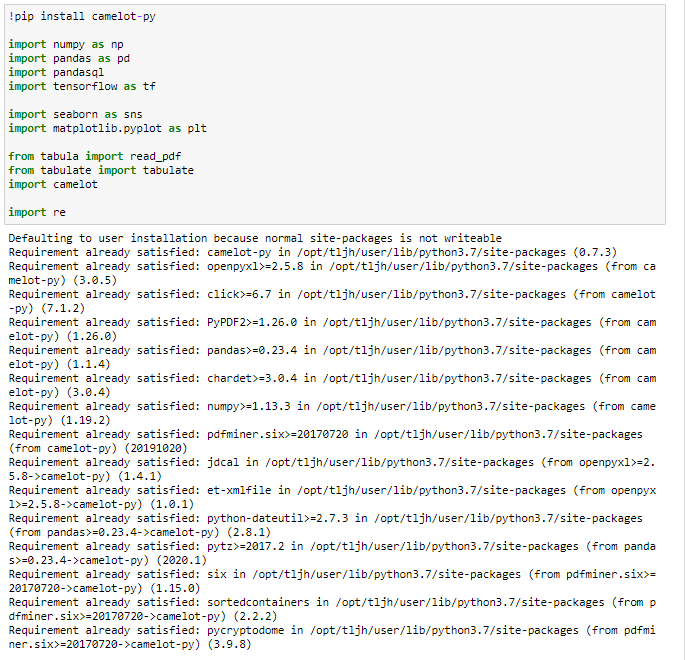
The first step that can be done is pre-coding or preparing the required libraries including pandas, numpy, tabula, tabulate, re, and Camelot, the details of the python code are in Picture 1.
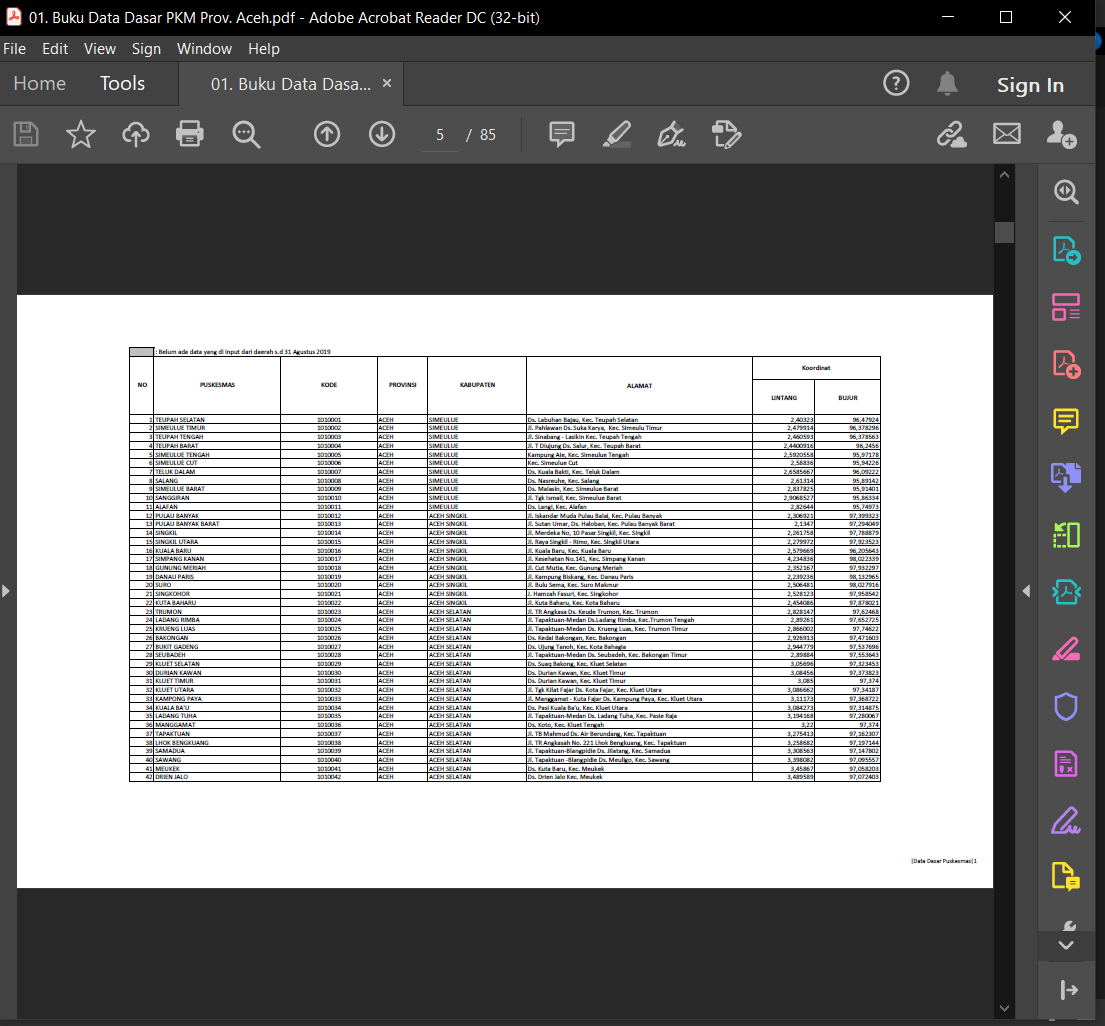
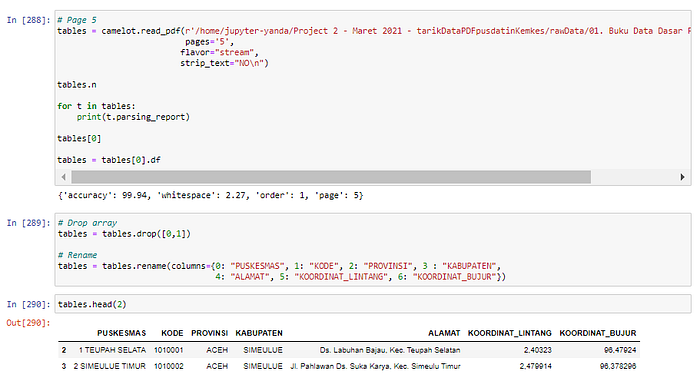
Then the next step is to extract the pdf data using python as shown in Picture 3. To read pdf files using Camelot don’t forget to add some parameters such as pages. After that, the important point of the tabular extract process using Camelot is parsing for our pdf file. Parsing means that the data we extract must first be parsed into the form of a list object, after that you can convert it into a dataframe form for example.
Please take a note, python cannot read pdf files directly. Therefore the parsing process is very important in this case, this needs to be done so that the python system can read and the data can be used for subsequent processes. After that we can do data cleansing for our dataframe. The process is clearer in Picture 1 — Picture 3.
Transpose Multiple Columns using Python
How to transform columns into rows in a dataframe using python this time begins by setting up the pandas library. With the framework or column and row attributes in the data as shown in Picture 4. Next, use the melt function to transform the columns into rows, using the melt method requires three parameters, namely id_vars, var_name, and value_name.

For Id_vars, we will set as a place to accommodate the code ID or unique code or primary code. var_name is the name of the new column that will be used to store the results of the column to row transformation. Finally, we will use value_name as a placeholder column for values that have been transformed to the previous column which will be the next row. For the detailed process, you can see in Picture 5.

That’s all about the explanation of Data Collection — Extract Tabular Data from PDF File using Python and Unpivot Table with Python that I can share, thank you for reading this article.
If you want to see the repository of all process that I have done from several project, click the google drive link below. You can download or just view it.
